




How to Write Airflow ETL - Intermediate Tutorial
Backfilling Missing Intermediate Airflow Material
A twitter friend reached out to me recently and he said:
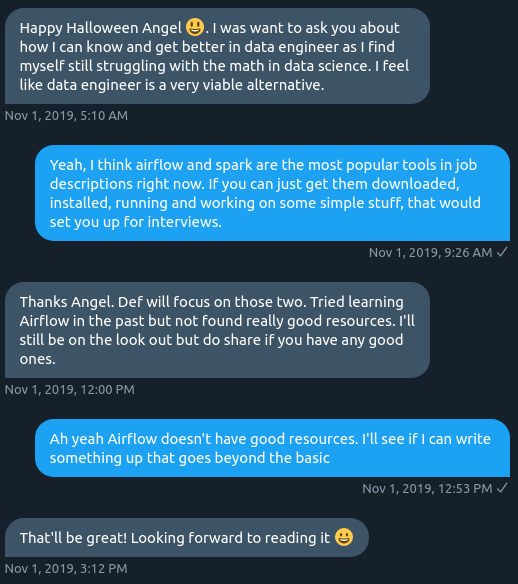
A simple extract and load job is a great example to go over in Airflow. Even though it is ultimately Python, it has enough quirks to warrant an intermediate sized combing through.
So that’s the reason we’re skipping regularly scheduled (boring to most) Database Normalization posts.
Actually, another fun reason for writing this:


Reading the Airflow documentation, while debugging your own scripts, is the best way to learn software like Airflow. This tutorial may get you started in that direction.
0.Imports
First thing you want to do in your main Airflow script file is import the important stuff. The DAG object, Variable, and Operator classes you need to talk to different data sources and destinations.
from airflow import DAG
from airflow.models import Variable
# to query our app database
from airflow.operators.mysql_operator import MySqlOperator
# to load into Data Warehouse
from airflow.operators.postgres_operator import PostgresOperator1.Variables
Next, you want to move your connections and sensitive variables over to Airflow. I recommend avoiding manual work here through the UI because you can essentially program your ETL from end to end, if you keep this all in scripts that can be executed in sequential order. I automate with Ansible, but that is another post.
Variables, which are usually strings or lists of strings for me, should be stored in a JSON file like so:
{
"AWS_ACCESS_KEY_ID": "secret",
"AWS_SECRET_ACCESS_KEY": "secret",
"s3_bucket": "secret",
"BI_TEAM": "[\"user1\",\"user2\",\"user3\",\"user4\"]"
}So that you can execute the following script to make these variables available:
airflow variables -i ~/dir/airflowvariables.jsonVariables are accessed with the Key part of JSON’s Key-Value pair structure. This is inside of our DAG script.
ACCESS_KEY_ID = Variable.get("AWS_ACCESS_KEY_ID")
SECRET_ACCESS_KEY = Variable.get("AWS_SECRET_ACCESS_KEY")
2.Connections
I highly recommend taking advantage of connections, rather than storing connection strings (ex: JDBC strings) in Variables. The reason is that MySQL and PostgreSQL operators are much easier to write than a PythonOperator in SQLAlchemy that may require your connection string in different Variables.
Loading your all of your connections in an instant does not have a default airflow command built in, as far as I know. A work-around I recommend, is to create a bash script like this:
#!/usr/bin/env bash
set -e
airflow connections -d --conn_id postgres_conn
airflow connections -d --conn_id mysql_conn
airflow connections -a --conn_id postgres_conn --conn_type postgres --conn_host 'host' --conn_schema 'schema' --conn_login airflow --conn_port '9999' --conn_password 'pw'
airflow connections -a --conn_id mysql_conn --conn_type mysql --conn_host 'host' --conn_schema 'schema' --conn_login airflow --conn_port '0000' --conn_password 'pw'In this way, our SQL operators will be much easier to write and execute, as you’ll see in the part 5. This bash file can be executed like so
~/dir/airflow_conns.shConnections are loaded inside of our DAG script like this. It is loaded differently from Variables.
APP_CONN_ID = "mysql_conn"
DW_CONN_ID = "postgres_conn"
3. DAG configuration
Most of these parameters are self-explanatory. Most of them.
default_args = {
"depends_on_past": True,
"wait_for_downstream": True,
"retries": 5,
"retry_exponential_backoff": True,
"start_date": datetime(2019, 1, 1),
"soft_fail": False,
"email_on_retry": False,
"email_on_failure": False,
"retry_delay": timedelta(minutes=5),
}
dag = DAG(
"dag_name",
catchup=True,
default_args=default_args,
schedule_interval="0 9 * * *",
)3a.Yes on Backfilling (Optional)
Robert Chang explains backfilling better than me:
Backfilling Historical Data
Another important advantage of using datestamp as the partition key is the ease of data backfilling. When a ETL pipeline is built, it computes metrics and dimensions forward, not backward. Often, we might desire to revisit the historical trends and movements. In such cases, we would need to compute metric and dimensions in the past — We called this process data backfilling.
If you are backfilling old data, then three DAG parameters become increasingly important.
start_date
catchup
schedule_interval
`start_date` is important because it is common to split up your backfilling by a date interval of some kind. For example, let’s say I want to backfill app data into our warehouse from January 1st, 2019:
"start_date": datetime(2019, 1, 1),
"schedule_interval"="0 9 * * *",
catchup=True,Then, our SQL queries depend on the execution date for each DAG created with catchup. Execution dates are created easily with airflow macros, but the way single and double quotes behave, I’ve had to do some finagling with `replace`. For example:
exec_date = '"{{ ds }}"'
sql_command = """
SELECT column
FROM table
WHERE condition = {date};
""".format(date=exec_date.replace('"', "'")3b.No on Backfilling
"start_date": datetime(YYYY, MM, DD), # doesn't matter
"schedule_interval"="0 9 * * *",
catchup=False,If you are doing simple extract and load of current data, no backfilling, then you really only care about schedule interval. This `schedule_interval` is 9 am UTC cron scheduling, so that makes it 4 am in Eastern Standard time. You don’t need macros for execution date, and start_date pretty much doesn’t matter. As far as I know.
4.SQL
extract_sql = """
SELECT INTO S3
CREDENTIALS
{strings}
""".format({strings}) # from part 1
load_sql == """
COPY table_name
FROM S3_FILE
CREDENTIALS
{strings}
""".format({strings}) # from part 1This is where Variables from part 1 become important. For example, S3 raw connection strings are easier to plug into a SQL string than a Connection Variable that I’ve only seen useful inside of an Operator default argument.
5.Operators
extract_data = MySQLOperator(
task_id="extracting_data",
sql=extract_sql, # from part 4
postgres_conn_id=APP_CONN_ID, # from part 2
dag=dag,
)
load_data = PostgresOperator(
task_id="loading_data",
sql=load_sql, # from part 4
postgres_conn_id=DW_CONN_ID, # from part 2
dag=dag,
)
# sets task sequence in DAG
extract_data >> load_data 6.Finale
Once you have a good foundation in Variables and Connections to most data sources you work with, then you become much more agile in writing new ETL.
Getting Variables and Connections locked down, allows you to execute whatever code you want into your Operators’ APIs or Databases. From there, you only have your code to blame because I know how tempting it can be to blame the tool.
Thanks for reading!





