
Designing Star and Snowflake Schemas
Digestible Data Modeling Blogging
Data Modeling is an important skill for any data worker to understand. Data Engineers in particular should understand this topic and be able to apply it to their work.
This post is a continuation of a data or dimensional modeling series. This series will probably have 5 parts. For pt.3 , we will go over the Design method section in Wikipedia’s page on Dimensional Modeling.
Design method.0 (Table of Contents)
Designing the model [edit]
The dimensional model is built on a star-like schema or snowflake schema, with dimensions surrounding the fact table.[3][4] To build the schema, the following design model is used:
Choose the business process
Declare the grain
Identify the dimensions
Identify the fact
Here, the star schema surfaces again. In pt.1, I briefly mention the star schema, and promise more details later. That time is now.
What is a Schema again?
Schema definition:
A database schema is the skeleton structure that represents the logical view of the entire database. It defines how the data is organized and how the relations among them are associated. It formulates all the constraints that are to be applied on the data.What is a Star Schema again?
You can think of the schema as the outline, or architectural plan of a database. It’ll often be used as synonymous with a visual diagram, which isn’t always the case. Schemas exist with, or without, drawings of them.
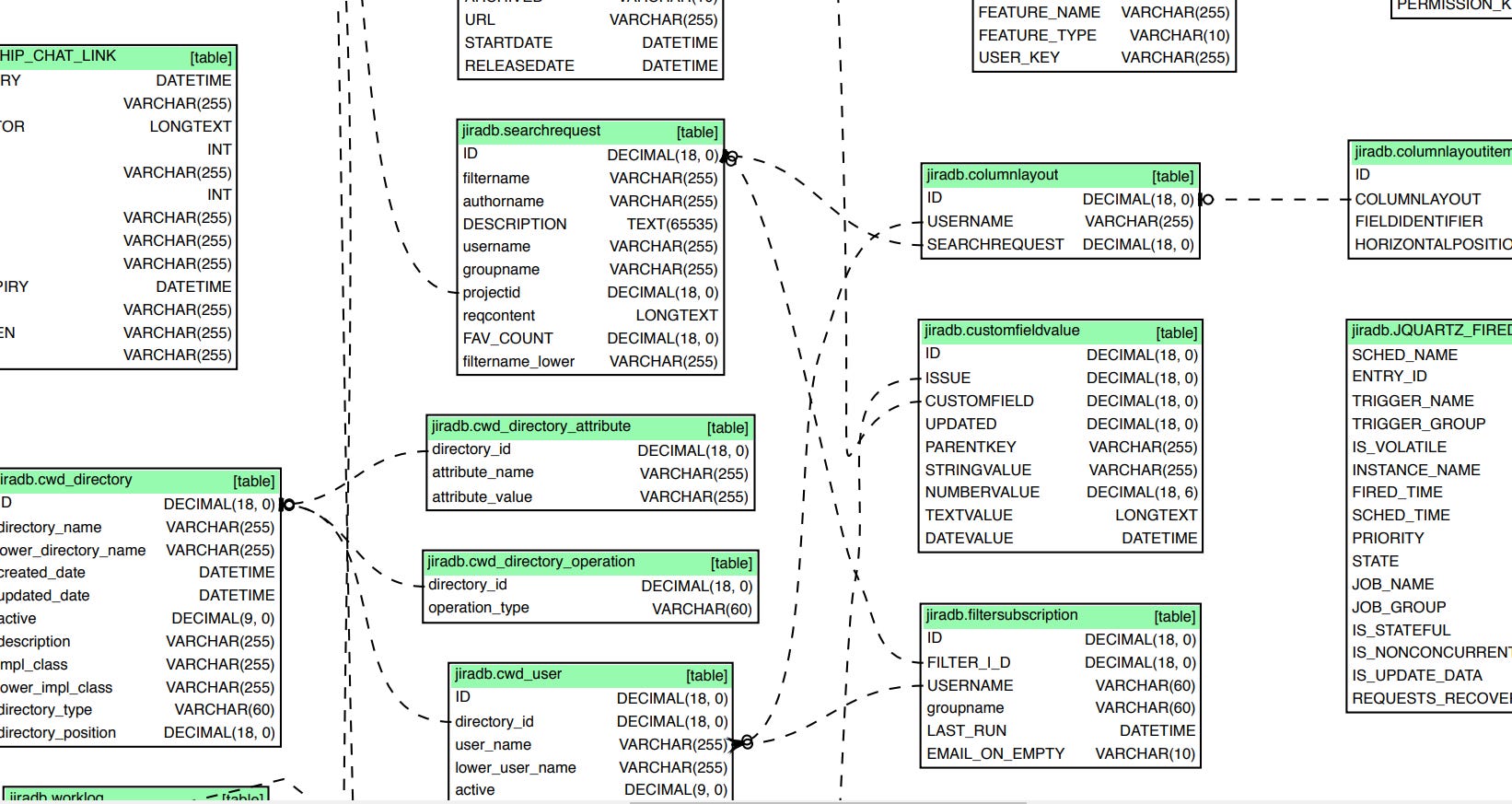
source: Jira, a software company, has uploaded their database schemas and can be viewed here. For fun.
What is a Star schema again?
The star schema is an old school, reliable way, to organize your tables and how they talk to each other in a data warehouse. It separates your tables between facts (numbers, loosely) and dimensions (strings or dates, loosely). All the facts are saved in a central fact table and all the dimensions are then partitioned out to their own dimension tables. The dimension tables surround the fact table, much like a star or snowflake, with relationships being defined by Primary and Foreign Keys (PK and FK, respectively).
Primary and Foreign Key examples:
PKs are unique identifiers like `student_id` would be a PK in the `student` table. Foreign Keys (FKs) are references to the PK in outsider tables. For example, if I buy a sandwich at my University’s cafe with funds on my `student_id`. The cafe’s record of my `student_id` is definitely not a unique identifier, but it does tie my information to that purchase.Primary and Foreign Keys are how these tables talk to each other and how relationships are set between tables.
Design method.1
Choose the business process
The process of dimensional modeling builds on a 4-step design method that helps to ensure the usability of the dimensional model and the use of the data warehouse. The basics in the design build on the actual business process which the data warehouse should cover. Therefore, the first step in the model is to describe the business process which the model builds on. This could for instance be a sales situation in a retail store. To describe the business process, one can choose to do this in plain text or use basic Business Process Modeling Notation (BPMN) or other design guides like the Unified Modeling Language (UML).
Beating a dead horse here but again, database specifications flow from the business’s needs. Not the other way around. Ideally.
Design method.2
Declare the grain
After describing the business process, the next step in the design is to declare the grain of the model. The grain of the model is the exact description of what the dimensional model should be focusing on. This could for instance be “An individual line item on a customer slip from a retail store”. To clarify what the grain means, you should pick the central process and describe it with one sentence. Furthermore, the grain (sentence) is what you are going to build your dimensions and fact table from. You might find it necessary to go back to this step to alter the grain due to new information gained on what your model is supposed to be able to deliver.
Grain is another word for how specific of a scope you want your dimensions and facts to have. This is definitely more of an art, than a science, in my opinion. Experienced data warehouse engineers will be able to succinctly define the grain of a data warehouse’s schema so that all tables captured serve it’s purpose.
Design method.3
Identify the dimensions
The third step in the design process is to define the dimensions of the model. The dimensions must be defined within the grain from the second step of the 4-step process. Dimensions are the foundation of the fact table, and is where the data for the fact table is collected. Typically dimensions are nouns like date, store, inventory etc. These dimensions are where all the data is stored. For example, the date dimension could contain data such as year, month and weekday.
Since there is only one fact table in a star schema, dimension tables are the ones who hold most of the relevant business data. You can think of dimensions as a fancy name for strings or dates.
Design method.4
Identify the facts
After defining the dimensions, the next step in the process is to make keys for the fact table. This step is to identify the numeric facts that will populate each fact table row. This step is closely related to the business users of the system, since this is where they get access to data stored in the data warehouse. Therefore, most of the fact table rows are numerical, additive figures such as quantity or cost per unit, etc.
Facts are stored in a central table, in the middle of a star schema. The fact table should be most closely related with the grain in Design method.2. Meaning, that it is the table that is most closely related with your business process or business questions that you want answered. The most common example is a `sales_fact` table, which stores all the numbers associated with sales.
Finale
This pt.3 goes into much further detail on how to build a star schema. The star schema is a fundamentally simple design with boundless opportunities for complexity. In the following pt.4, normalization and de-normalization. We will cover when to strategically break these schema rules and conformed dimension rules from pt.2!