

Denormalization And A Welcome Back
Denormalization And A Welcome Back
Data Modeling part 9 / Normalization part 5
First, Housekeeping
Quite a lot has changed since my last post on March 2, 2021.
I helped Stripe close out the 4th of 4 Quarters (2021Q1) of online payment hyper-growth
Took a nice well deserved break
Because of our business success and in an effort to reclaim our writing differentiation, I changed the name of this newsletter back to Music and Tech from Modern Data Infrastructure.
Getting into it
Data Modeling is an important skill for any data worker to understand. Data Engineers in particular should understand this topic and be able to apply it to their work. Normalization is an important part of Data Modeling and part one of my Normalization series can be found here.
For this post, we will be going over the examples of how normalization works in practice. I will also be reviewing foreign-primary key relationships, as they are the crux of how normalization (increasing normal forms) and denormalization (decreasing normal forms) works.
pt 5: Denormalization in Practice (this post)
I recommend you have a fundamental understanding of foreign key relationships and why we would want to normalize a dataset before continuing.
What are denormalized tables for?
Denormalized tables are useful in executive metrics and dashboards. Raw data is often large, slow, and computationally expensive to read. By paying an upfront cost on writing analytics to a denormalized table, analytics are made ready to serve for consumers who turn information into insights.

Denormalization improves query speed, or read-performance, of a database by combining redundant data into tables that are shaped wide (many columns) and short (not as many rows). Raw data or source tables can be dim.customer, fact.sales, dim.salesperson, dim.manager, etc. But a denormalized table would look more like denormalized.last_month_sales_and_customers.
*very roughly: the dim, fact, and denormalized database objects here, are schemas. A schema is a folder for tables that belong in the same general mental model.
More on facts and dimensions in part 2 of the whole data modeling series.
Differences between Normalization and Denormalization
From my previous post in this series, Dataset Normalization in Practice.
Normalization is represented through “normal forms” which increase from first to third, with a special case not covered here (Boyce-Codd Normal form - BCNM).
Meaning, datasets or tables are split up into increasingly discrete database objects such as columns, tables, and key references.
Denormalization does the opposite. Denormalization of data is to combine, rather than split up, multiple sources of data into digestible datasets. These denormalized tables provide information about key business questions in one place. An example question is; who were our top customers last month and which were the sales teams that brought them in?
Using that question as an example, these are the hypothetical source tables one would need to combine in order to make a denormalized dataset: Customers, Sales (Sales date), Sales_person, Sales_team.
Action - Adventure - Humongous Ape
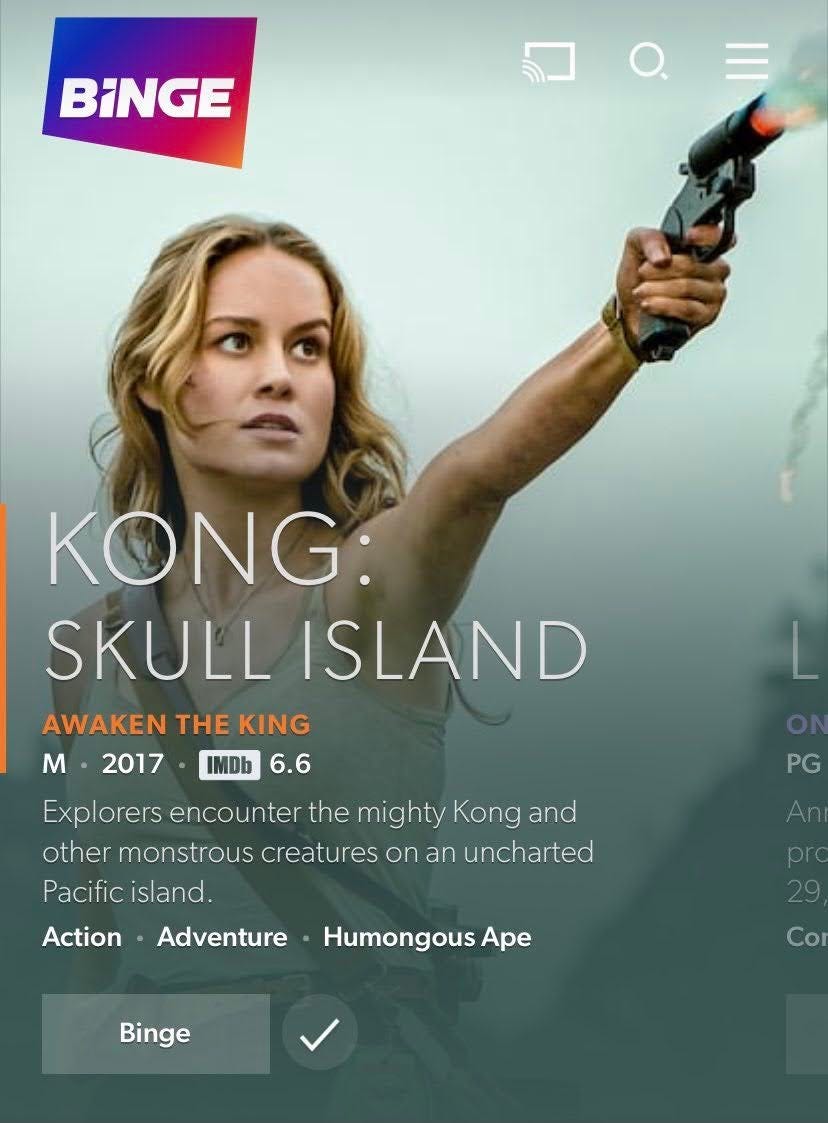
Action - Adventure - Humongous Ape
This looks like a 1 row, 3 column table.
And you would think that the table name is something like Genre until the Humongous Ape value appears. This is likely a mistake but an amusing potential example of denormalization: A table made wide (more columns) because the information it’s presenting, spans more topics than only genre.
This single row, denormalized, table may be answering the question,
Which
Actionmovies with any secondarygenrevalue, also haveHumongous Apesin them?
Finale
Denormalized tables are useful in providing holistic views of business sectors and key business questions. In a rapidly changing industry with constantly newer (and expensive) technologies, it is important to remember the fundamentals of business. Where are we increasing revenue and where are we reducing costs?
Denormalization of data helps in both reducing computational costs and providing views into these kinds of questions.
Curated Content
PostgreSQL and Docker
These two Postgres plus Docker tutorials are handy in getting your own database server up and running on a Linux server.
About the Author and Newsletter
At Music and Data , I democratize the knowledge it takes to understand an open-source, transparent, and reproducible Data Infrastructure. In my spare time, I collect Lenca pottery, walk my dog, and listen to music.
More at; What is Music and Tech.